
Here at Moz we have committed to making Link Explorer[1] as similar to Google as possible, specifically in the way we crawl the web. I have discussed in previous articles some metrics we use to ascertain that performance[2], but today I wanted to spend a little bit of time talking about the impact of robots.txt and crawling the web.
Most of you are familiar with robots.txt[3] as the method by which webmasters can direct Google and other bots to visit only certain pages on the site. Webmasters can be selective, allowing certain bots to visit some pages while denying other bots access to the same. This presents a problem for companies like Moz, Majestic[4], and Ahrefs[5]: we try to crawl the web like Google, but certain websites deny access to our bots while allowing that access to Googlebot. So, why exactly does this matter?
Why does it matter?
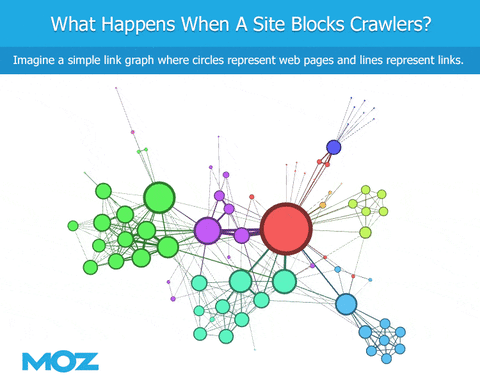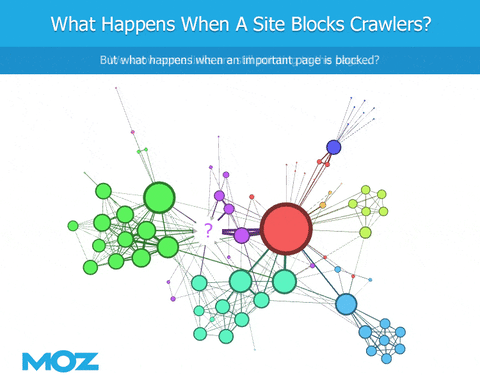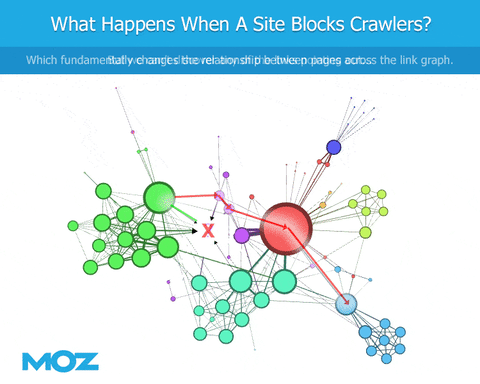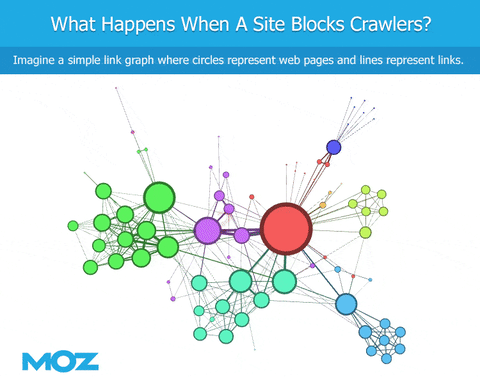
As we crawl the web, if a bot encounters a robots.txt file, they're blocked from crawling specific content. We can see the links that point to the site, but we're blind regarding the content of the site itself. We can't see the outbound links from that site. This leads to an immediate deficiency in the link graph, at least in terms of being similar to Google (if Googlebot is not similarly blocked).
But that isn't the only issue. There is a cascading failure caused by bots being blocked by robots.txt in the form of crawl prioritization. As a bot crawls the web, it discovers links and has to prioritize which links to crawl next. Let's say Google finds 100 links and prioritizes the top 50 to crawl. However, a different